您现在的位置是:亿华云 > IT科技
MySQL 大批量插入,如何过滤掉重复数据?
亿华云2025-10-03 02:33:05【IT科技】5人已围观
简介加班原因是上线,解决线上数据库存在重复数据的问题,发现了程序的bug,很好解决,有点问题的是,修正线上的重复数据。线上库有6个表存在重复数据,其中2个表比较大,一个96万+、一个30万+,因为之前处理

加班原因是批量上线,解决线上数据库存在重复数据的插入问题,发现了程序的何过bug,很好解决,滤掉有点问题的重复是,修正线上的数据重复数据。
线上库有6个表存在重复数据,批量其中2个表比较大,插入一个96万+、何过一个30万+,滤掉因为之前处理过相同的重复问题,就直接拿来了上次的数据Python去重脚本,脚本很简单,批量就是插入连接数据库,查出来重复数据,何过循环删除。
emmmm,但是这个效率嘛,实在是太低了,1秒一条,重复数据大约2万+,预估时间大约在8个小时左右。。香港云服务器。
盲目依靠前人的东西,而不去自己思考是有问题的!总去想之前怎么可以,现在怎么不行了,这也是有问题的!我发现,最近确实状态不太对,失去了探索和求知的欲望,今天算是一个警醒,颇有迷途知返的感觉。
言归正传,下面详细介绍去重步骤。
CREATE TABLE `animal` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `pilipa_dds`.`student` (`id`, `name`, `age`) VALUES (1, cat, 12); INSERT INTO `pilipa_dds`.`student` (`id`, `name`, `age`) VALUES (2, dog, 13); INSERT INTO `pilipa_dds`.`student` (`id`, `name`, `age`) VALUES (3, camel, 25); INSERT INTO `pilipa_dds`.`student` (`id`, `name`, `age`) VALUES (4, cat, 32); INSERT INTO `pilipa_dds`.`student` (`id`, `name`, `age`) VALUES (5, dog, 42);目标:我们要去掉name相同的数据。
先看看哪些数据重复了
SELECT name,count( 1 ) FROM student GROUP BY NAME HAVING count( 1 ) > 1;输出:
name count(1) cat 2 dog 2
name为cat和dog的数据重复了,每个重复的数据有两条;
Select * From 表 Where 重复字段 In (Select 重复字段 From 表 Group By 重复字段 Having Count(1)>1)
删除全部重复数据,一条不留
直接删除会报错
DELETE FROM student WHERE NAME IN ( SELECT NAME FROM student GROUP BY NAME HAVING count( 1 ) > 1)报错:
1093 - You cant specify target table student for update in FROM clause, Time: 0.016000s
原因是:更新这个表的同时又查询了这个表,查询这个表的同时又去更新了这个表,可以理解为死锁。云服务器mysql不支持这种更新查询同一张表的操作
解决办法:把要更新的几列数据查询出来做为一个第三方表,然后筛选更新。
DELETE FROM student WHERE NAME IN ( SELECT t.NAME FROM ( SELECT NAME FROM student GROUP BY NAME HAVING count( 1 ) > 1 ) t)删除表中删除重复数据,仅保留一条
在删除之前,我们可以先查一下,我们要删除的重复数据是啥样的
SELECT * FROM student WHERE id NOT IN ( SELECT t.id FROM ( SELECT MIN( id ) AS id FROM student GROUP BY `name` ) t )啥意思呢,就是先通过name分组,查出id最小的数据,这些数据就是我们要留下的火种,那么再查询出id不在这里面的,就是我们要删除的重复数据。另外,关注Java知音公众号,回复“后端面试”,送你一份面试题宝典!
开始删除重复数据,仅留一条
很简单,刚才的select换成delete即可
DELETE FROM student WHERE id NOT IN ( SELECT t.id FROM ( SELECT MIN( id ) AS id FROM student GROUP BY `name` ) t )90万+的表执行起来超级快。
All done
服务器租用很赞哦!(1)
相关文章
- 世界越来越热,数据中心可不能跟着升温
- 互联网中的地址是数字的IP地址,域名解析的作用主要就是为了便于记忆。
- 当投资者经过第二阶段的认真学习之后又充满了信心,认为自己可以在市场上叱咤风云地大干一场了。但没想到“看花容易绣花难”,由于对理论知识不会灵活运用.从而失去灵活应变的本能,就经常会出现小赢大亏的局面,结果往往仍以失败告终。这使投资者很是困惑和痛苦,不知该如何办,甚至开始怀疑这个市场是不是不适合自己。在这种情况下,有的人选择了放弃,但有的意志坚定者则决定做最后的尝试。
- 投资各类域名就像到处打游击战,结果处处失败。因为这样,对任何一个中国域名市场的走势和价格都没有准确的把握,所以最好缩小范围,准确把握战场态势,埋伏。
- 5G如何影响数据中心以及如何做好准备
- 当投资者经过第二阶段的认真学习之后又充满了信心,认为自己可以在市场上叱咤风云地大干一场了。但没想到“看花容易绣花难”,由于对理论知识不会灵活运用.从而失去灵活应变的本能,就经常会出现小赢大亏的局面,结果往往仍以失败告终。这使投资者很是困惑和痛苦,不知该如何办,甚至开始怀疑这个市场是不是不适合自己。在这种情况下,有的人选择了放弃,但有的意志坚定者则决定做最后的尝试。
- 主流搜索引擎显示的相关搜索项越多,越能积极反映该域名的市场价值。同时,被评估域名的搜索引擎显示结果不佳可能是由于以下两个原因:
- 2、定期提交和投标域名注册。例如,益华网络点击“立即预订”后,平台会抢先为客户注册域名。当然,一个域名可能会被多个客户预订,所以出价最高的人中标。
- 确保备用电源的三个步骤
- 一下域名,看有没有显示出你所解析的IP,如果有,就说明解析是生效的;如果没有,就说明解析是不生效的。
热门文章
站长推荐
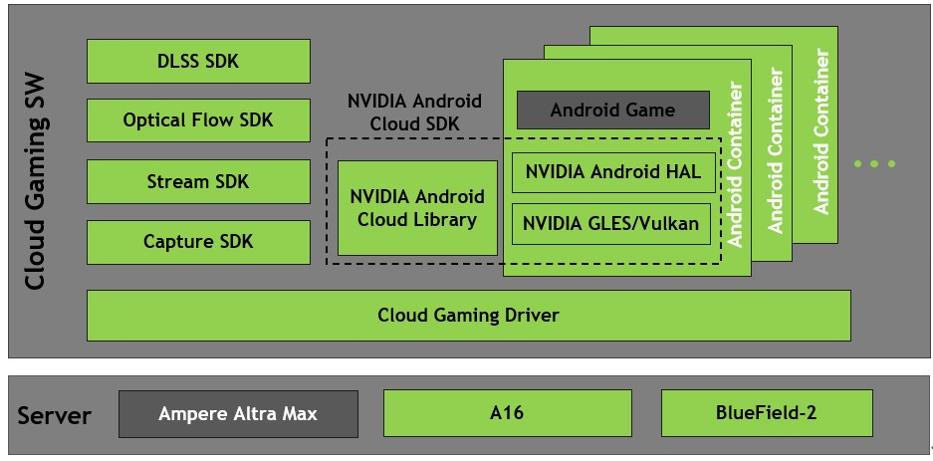
NVIDIA 与 Ampere Computing 携手创建用于云游戏的Arm 架构云原生服务器平台

2016年1月1日:注册价格将降至每年7欧元。

4、域名传输时,取决于域名原始用户的邮箱是否有效,以及他是否将密码发送到此邮箱。

前面这两个步骤都是在本机完成的。到这里还没有涉及真正的域名解析服务器,如果在本机中仍然无法完成域名的解析,就会真正请求域名服务器来解析这个域名了。
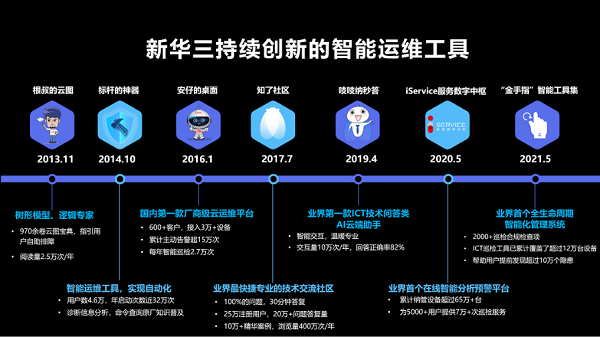
十年磨一剑:新华三智能运维工具集的演变之路

第三,.cc域名域名也有很多优势资源域名,从整体注册基数也可以由此推断;

a、变更前的公司证件扫描件(代码证或者营业执照)及联系人身份证复印件、变更后的公司证件扫描件(代码证或者营业执照)及新的联系人身份证复印件;身份证复印件需本人签名,公司证件复印件需加盖公章。

域名和网址一样吗?域名和网址有什么区别?