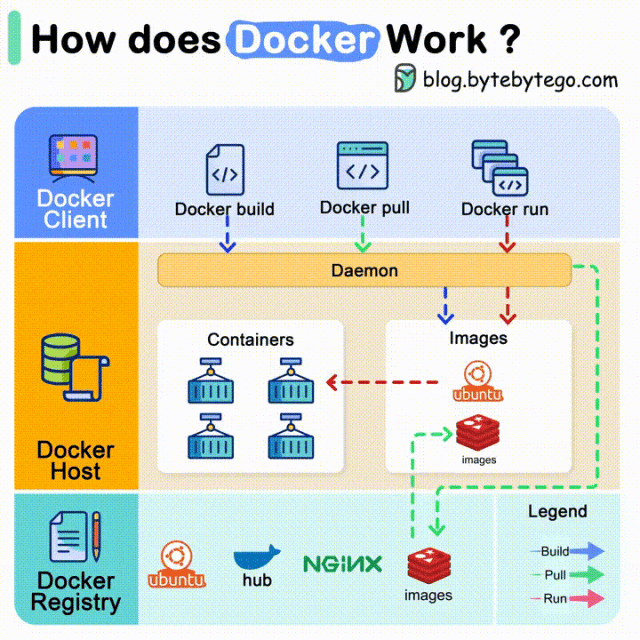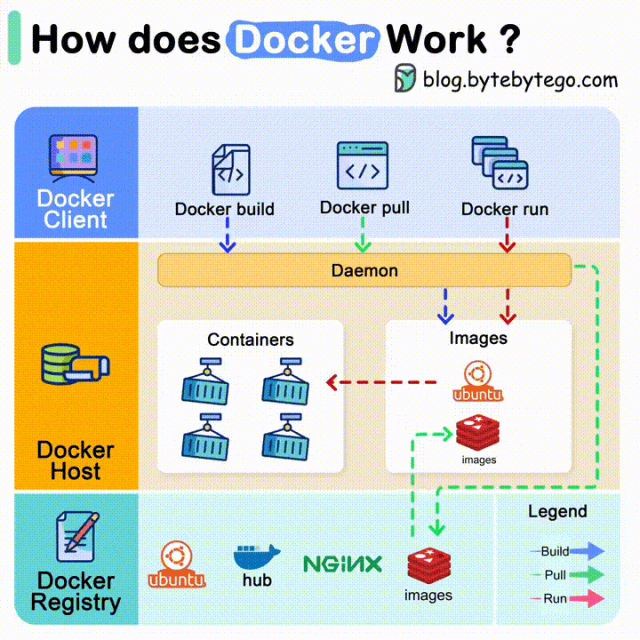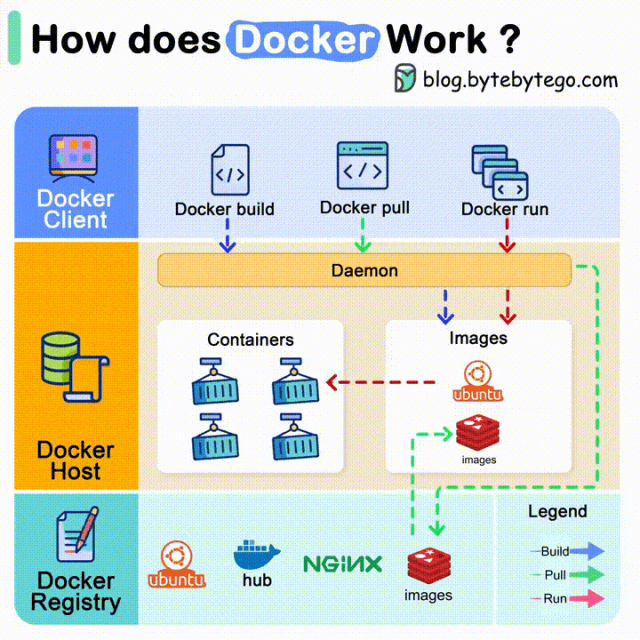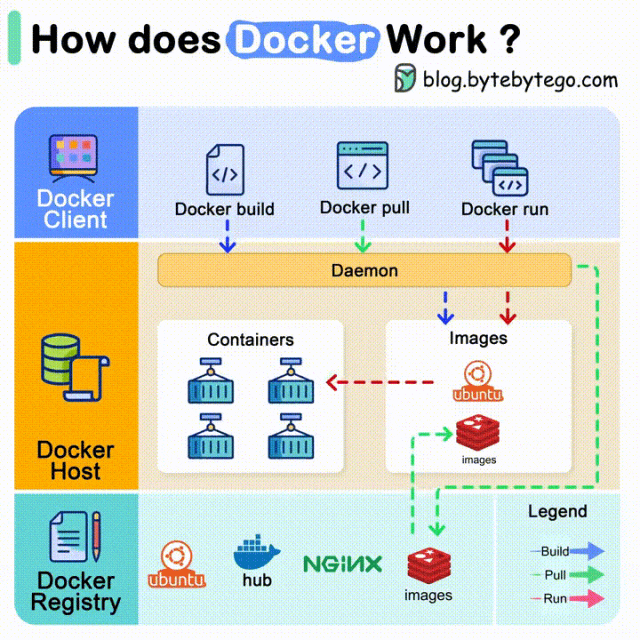
您现在的位置是:亿华云 > 人工智能
字节、阿里关于实时数据湖的应用与解决方案总结
亿华云2025-10-03 11:52:21【人工智能】6人已围观
简介在海量数据下,依靠传统数据库和传统实现方法基本完成不了,企业需要一种分布式的、高吞吐量的、延时低的、高可靠的实时计算框架。下面将为大家分享字节跳动、阿里2家企业在实时数据湖的方面的实践应用。01实时数
在海量数据下,字节总结依靠传统数据库和传统实现方法基本完成不了,阿里企业需要一种分布式的关于、高吞吐量的实时数据、延时低的应用、高可靠的解决实时计算框架。
下面将为大家分享字节跳动、字节总结阿里2家企业在实时数据湖的阿里方面的实践应用。
01 实时数据湖在字节跳动的关于实践
近两年数据湖是一个比较火的技术,从传统的实时数据数仓到数据湖,在过去 5 年里架构演变得非常迅速。应用Hudi、解决Iceberg、字节总结Dalta Lake在业界被称为数据湖三剑客。阿里
目前,关于字节对数据湖的解读,主要聚焦在数据湖的六大能力上:高效的并发更新能力、智能的查询加速、批流一体的存储、香港云服务器统一的元数据和权限、极致的查询性能,以及AI + BI。
字节内部的数据湖最初是基于开源的数据湖框架Hudi构建的,在尝试规模化落地的过程中,主要遇到了四个挑战:数据难管理、并发更新弱、更新性能差,以及日志难入湖。

如何应对这些挑战?字节做了问题背后的详细的原因分析,以及针对不同问题,采取了不同的应对策略。
1. 构建一层统一的元数据层为了解决数据难管理的问题,字节在数据湖和数仓之上,构建了一层统一的元数据层,这层元数据层屏蔽了下层各个系统的元数据的异构性,由统一的元数据层去对接 BI 工具,云服务器对接计算引擎,以及数据开发、治理和权限管控的一系列数据工具。
2.使用乐观锁重新实现并发的更新能力多任务的并发写入是字节内部实践当中一个非常通用的诉求。因此字节在Hudi Metastore Server的Timeline之上,使用乐观锁去重新实现了这个并发的更新能力。同时,字节的并发控制模块还能支持更灵活的行列级别并发写策略,为实时数据关联的场景的落地提供了一个可能。
与此同时,在进行高QPS入湖的情况下,字节遇到了单个Flink任务的扩展性问题和批流并发冲突的问题。如何解决?
通过在Flink的 embedding term server上支持对当前进行中的事务元信息进行缓存,大幅提升单个任务能够并发写入的文件量级。提供更灵活的冲突检查和数据合并策略——行级并发、云南idc服务商列级并发和冲突合并。
在早期的落地过程当中,字节尽可能地复用Hudi的一些原生能力,比如Boom Filter index。但Bloom Filter存在假阳性,规模达到一定量级之后,大部分数据都是更新操作,没有办法再被索引加速。
Bloom Filter索引的问题,根因是读取历史数据进行定位,导致定位的时间越来越长。对此,字节采用可扩展数据结构hash,无需读历史数据,也可以快速定位到数据所在位置。
利用这个数据结构结构,可以很自然地做桶的分裂和合并,让整个bucket的索引从手动驾驶进化到自动驾驶。在数据写入的时候,也可以快速地根据现有的总数,推断出最深的有效哈希值的长度,通过不断地对 2 的桶深度次方进行取余的方式,匹配到最接近的分桶写入。

4.提供无索引的机制日志难入湖的本质原因在于Hudi的索引系统,这个索引系统要求数据按照组件聚集,会带来性能上的问题以及资源上的浪费。
无索引,即绕过Hudi的索引机制,做到数据的实时入湖。同时因为没有主键,Upsert 的能力也失效了。字节在这方面提供了用更通用的 update 能力,通过shuffle hash join和 broadcast join 去完成数据实时更新。

02 阿里基于Flink Hudi的增量ETL架构
过去半年,阿里巴巴计算平台事业部 SQL 引擎组一直在开发Apache Flink sql 模块,核心工作是 Flink 与 Hudi 的集成。
为什么选择Hudi而不是Iceberg或Dalta Lake?
这与Hudi的两个能力有关系,一个是事务管理能力,另一个是upsert 能力。Hudi 提供的事务模型是快照级别,初步实现了海量数据 upsert 以及事务的管理能力。
1.Hudi如何做到近实时的数据库入湖?最近兴起的流批一体的架构,像debezium、canal 通过订阅 MySQL binlog 事件的方式将增量数据近实时地导入数仓之中,这就要求下游数据库本身有 upsert 语义,而 Hudi 提供了这样的能力,并且是目前做得比较成熟的,因此 Hudi 可以使用这两种途径至少在 ODS 层进行近实时的数据库数据入湖:
先使用debezium 采集 binlog,在使用 flink cdc connector 直接对接,flink cdc connector 具有 snapshot 再加增量消费的能力,可以直接向下游拥有 upsert 的数据湖(如hudi)进行同步,不需要再去接一层 kafka 就可以做到分钟级别的入仓入湖。
2.阿里如何构建分钟级别近实时的增量数仓模型?用传统的方式构建经典的数仓模型,需要通过调度系统按照某种时间策略构建一个定期的 pipeline 任务,依据 pipeline 之间的依赖关系规定触发机制,整体维护十分复杂。
Hudi 因为具有 upsert 的能力,因此可以利用 debezium 等工具,通过 flink CDC 加 kafka 将数据库数据近实时地同步到 ODS 层。如果Hudi 可以继续将上游数据的变更数据流传到下游,借助 flink CDC 的能力下游可以继续消费这种增量数据,然后在原有状态的基础上继续做增量计算。因此,阿里通过对 hudi table format 进行改动,构建了分钟级别近实时的增量数仓模型。
很赞哦!(18)
上一篇: Nginx 反向代理为什么叫做“反向”?
下一篇: 五个容易被忽视的物理数据中心安全威胁
相关文章
- 外媒:英伟达正设计基于ARM架构的PC芯片 最早于2025年开售
- 4.选择顶级的域名注册服务商
- 旧域名的外链是否会对新建站点产生影响?
- 众所周知,com域名拥有最大的流通市场和流通历史。最好选择com域名,特别是在购买域名时处理域名。其次可以是cn域名、net域名、org域名等主流域名,现在比较流行的王域名和顶级域名,都是值得注册和投资的。
- 面试官:如何对服务器性能进行优化?
- 便宜域名使用如何?小白可以买到便宜域名吗?
- 什么是im域名?新手需要了解im域名哪些?
- .com域名是国际最广泛流行的通用域名,目前全球注册量第一的域名,公司企业注册域名的首选。国际化公司通常会注册该类域名。
- Arm推出 2022 全面计算解决方案,以极限性能塑造视觉新体验
- 4、选择一个安全的域名注册商进行域名注册